Civic dashboards powered by hundreds of data sources
Community Performance
Dashboard
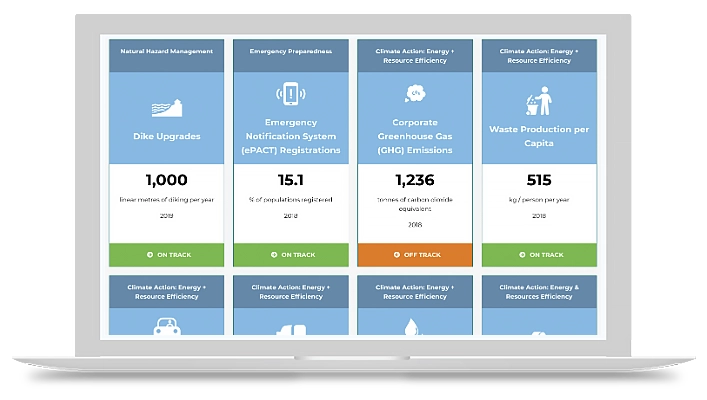
It’s never been more important to foster transparent communication with your community. But how can you create that conversation? Our Community Performance Dashboard is the best way to inform your citizens through customizable key performance indicators.
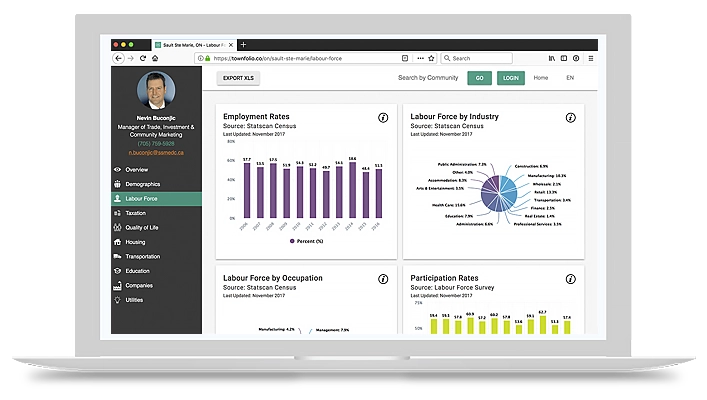
No more data updates, PDFs, or Excel charts. Economic Development Dashboard updates your community profile from the most trusted and current data with the click of a button. Verify your profile to tell your story and add in custom data to showcase your municipality. The Economic development Dashboard’s visitor base is global and generates real leads ranging from entrepreneurs to large companies
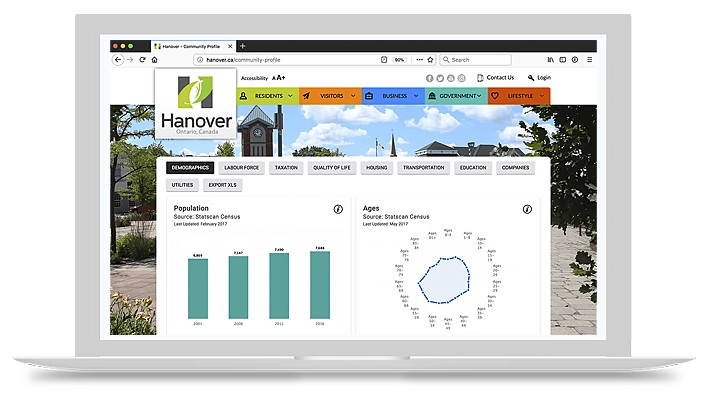
Like community profiles, but powering your website at a price point your municipality can afford. Add even more custom data, let site selectors export raw data, or download charts for your next report. With one line of code, Economic Development Dashboard powers your website with up-to-date data on your municipality.